
today I’m going to talk to you about HTTP, which is the common language of the web. You’re probably familiar with the four methods that represent a RESTful web interface, so PUT, GET, POST, and DELETE. But there are a lot of intricacies with HTTP, a lot of wrinkles in the client-to-server transaction that I wanted to talk about. Given that the specs were just changed for the first time in 16 years, less than a year ago, I thought it would be a good time to dive into HTTP and what’s changed about it.
So, the crux of HTTP is that every client, if it wants to communicate with the server, has to send out a request in a way that the server can understand, and that server has to send back a response in a similarly and uniformly formatted message. Every request is going to have a start line and headers. The start line has the method, so what you want HTTP to do for you, and it’s going to have the location of the resource. The headers are about content negotiation, like how you want the server to bring information back to you. On the response end, the server also has to send out a start line and headers, but the server always has to send a body as well, unless you use the HEAD method that I’ll talk about later.
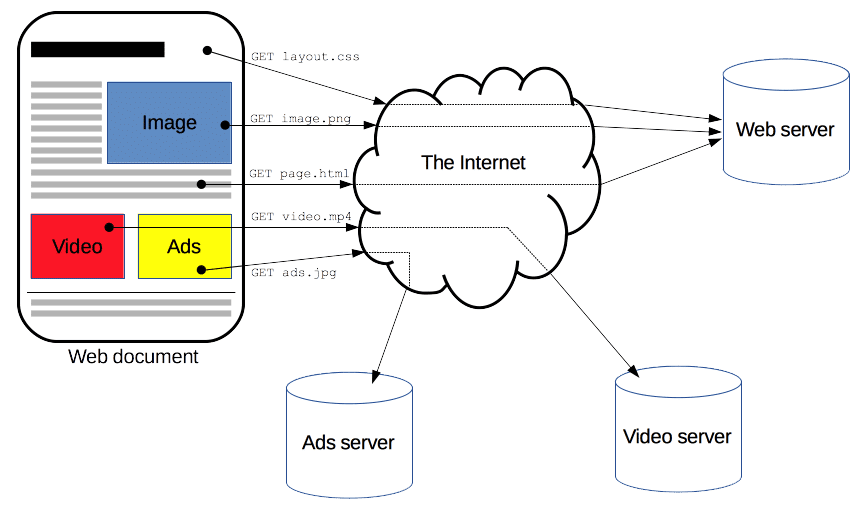
When you type in the URI into your browser, the first thing that happens is the browser is just going to split it into the scheme, the server internet address, and the name of the resource you want to access. The server internet address can be thought of as an alias or the actual IP address of the server, in the same way that 5 Hanover Square is an alias for the lat/long of Full-Stack.
It’s important also to understand where HTTP fits into the internet architecture. The best mental model that I could surmise here is that HTTP is layered over TCP. So, we can think of HTTP as a car, TCP is like the roads that it travels over, and IP is like the coordinate system that the roads are layered over. Beyond that, the data link layer would just be like Earth or some physical representation. The only complication that makes this model a little bit inelegant is that every time that the HTTP passes over TCP, the TCP connection opens and closes. So, the TCP connection does not stay active after the messages have been transmitted.
There are five components of HTTP that I want to briefly touch on during this talk: proxies, caches, gateways, tunnels, and agents. These are the five intermediaries that will make the transaction between a client and a server less of a one-to-one request and response transmission. Proxies and caches are by far the most common. They are going to be on almost every site that you visit, and they will send you to at least two proxies on the way.
So, how does HTTP find its way to a proxy? You can either set up a proxy on the client side, which would be like an explicit content proxy that would filter, say, adult content from the server coming back to the client, or on the server side, you could have a proxy that filters out malicious attacks. It’s often used for security to intercept traffic and ensure that it’s valid. Because there are often more than two proxies in a chain, it’s often important to debug what’s happened to requests along the chain. There are two ways to really suss out what’s happening to the message. The first is to run the TRACE method, which shows you along the proxy chain how the request is being altered. In this case, TRACE would show you that the identifying information was removed from the request at this proxy. The Via header is just a list of the different proxies in the chain.
Another really popular type of proxy is just caches. These are just storehouses of popular documents on a site. One reason that this is incredibly popular is because if you’re accessing a server from the other side of the country, there’s enough space between you that the speed of light becomes a speed consideration in terms of file transmission. So, if everything is moving optimally and a resource is only taking the speed of light to travel back and forth, that’s still a round-trip of 30 milliseconds. And if you have 250 images on the page, that’s going to add up to a noticeable lag. What happens is a site will cache the resources on closer servers and actually serve up those resources to you rather than having the request go all the way across the country. The most important consideration here is how fresh what’s on the cache is compared to what’s on the server. Because if you have a resource on your site that was updated a year ago, but the cache is 2 years old, then HTTP needs to know that the document it’s serving up is fresh and doesn’t need to be revalidated. Sometimes there are headers on the request message that are explicit about when a resource is going to expire. But if that doesn’t exist, then HTTP can algorithmically determine whether it’s a fresh document.
Gateways are another wrinkle in the server-to-client model. Gateways are used when you want to communicate with an HTTP protocol or one protocol that the server you’re trying to communicate with uses a different protocol. So, the server might be an FTP server, and you want to access it through the web, so you want to use HTTP. It has to go through an HTTP to FTP gateway.
Tunnels are basically just allowing you to transmit data in one protocol across another protocol. So, like SSL will be transmitted across the HTTP protocol to the server. The reason this is important, at least the reason why HTTP uses this method, is because if that message is ever intercepted, it will just read as encrypted data like the SSL still traveling across the HTTP protocol, but because it’s encrypted, if it’s ever intercepted, no one can decrypt that.
Before SSL can travel across HTTP, it needs to perform something called a client handshake with the server, where the client and the server are essentially just agreeing on a way to encrypt the data. That way, only the server and the client know which encryption algorithm they’re using, which is usually symmetric cryptography.
Very quickly, I just want to review some of the changes with the new protocol that was just introduced last year. HTTP messages are now transmitted as binary data instead of textual data. The headers are compressed, which is a really important consideration for mobile. Servers are now able to push content proactively into a client cache. So, if you request an HTML page and that page links to several source files, like a CSS style sheet or something, the server will know that you’re going to want to fetch that eventually, so it will just send that file over along with the initial HTML that you’re requesting.
These are some of the resources that I used. I think, by far, the most helpful resource for understanding HTTP is the network tab of the Chrome DevTools because it will show you every HTTP request that you’re making on a page, the amount of time that that request took, and everything.
Thank you!